Conclusion
The traveling artilleryman problem is NP-hard, but we have developed two heuristic algorithms, Nearest Neighbor and Random Neighbor, that can produce good solutions reasonably fast for problems of modest size. We have also developed a simple “overgreedy” algorithm that calculates a lower bound of the solution cost for a given cardinality (number of positions used).
We have also discovered a way to analyze conflicts between positions in a TAP instance via maximum independent sets. In this way, one can find positions that cannot possibly be used by an optimal solution, and by removing these, one can improve the performance of the heuristic algorithms.
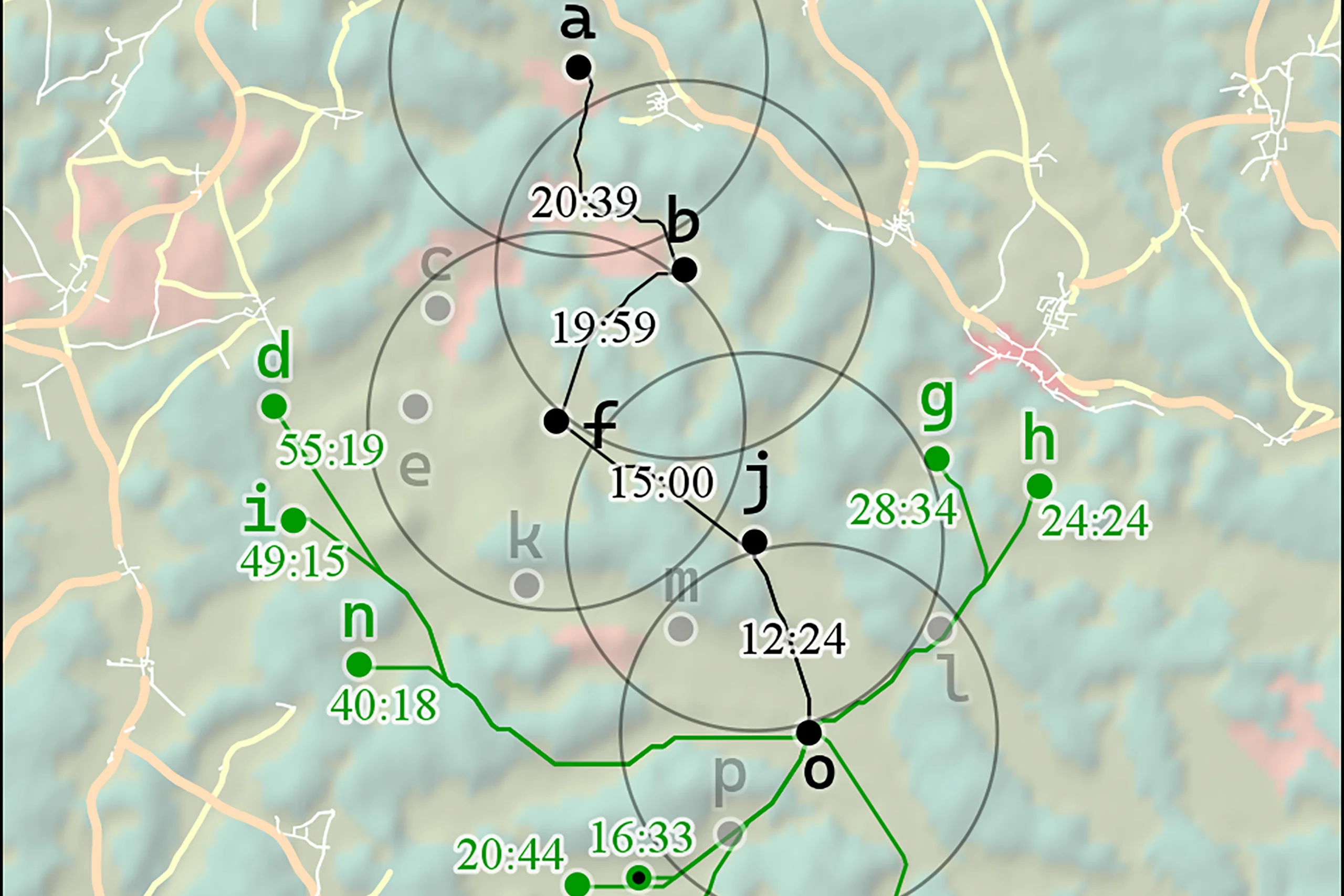
We have tested our algorithms and our conflict analysis on three TAP instances with 20 positions each, and measured running time and solution quality. Running our Nearest Neighbor algorithm or Random Neighbor algorithm once on one of our TAP instances takes about 3 seconds in our implementation, but in general the time will depend on many factors like the number of positions, the size of the search area, and the terrain resolution.
Measuring solution quality was problematic. For a solution of optimal cardinality (the number of positions used), we would have preferred to define its quality as the percentage by which its cost exceeds the cost of an optimal solution. But we could not measure that percentage, since we do not know the optimal solutions.
We do have the simple algorithm that can calculate a lower bound for the cost of an optimal solution, so we can measure the percentage by which the cost of a solution exceeds the lower bound, but we believe that our lower bounds are not very tight. So, instead of comparing with the optimal solution or a lower bound, we compare with a “winning” solution: the best solution we have found by running the Random Neighbor algorithm many thousands of times on the problem instance.
By this metric, the Nearest Neighbor algorithm produced an excellent result for one of our TAP instances, but produced mediocre and poor results for the two others. The average quality of solutions from the Random Neighbor algorithm depends on how choices are randomized, which can be done in many ways. We have explored one way that uses a bias function that assigns probability weights to alternative choices depending on their cost.
We have not found a single bias function that outperforms all others on our TAP instances, but we found several that give a decent probability of finding a “top-tier” solution: that is, a solution of the highest cardinality with a cost not more than 10% higher than the winning solution from thousands of tests.
Although the top-tier probability can be low for a single use of Random Neighbor, one should get quite a good chance by repeating Random Neighbor thirty times.